|
Опрос
|
реклама
Быстрый переход
«Сбер» открыла для всех ИИ-генератор 6-секундных видео Kandinsky Video 1.1
28.05.2024 [21:12],
Владимир Фетисов
«Сбер» официально объявил о запуске бета-версии нейросети Kandinsky Video 1.1, которая способна создавать полноценные видео продолжительностью 6 секунд на основе текстового описания или статического изображения. Оценить возможности алгоритма можно на платформе fusionbrain.ai и в Telegram-боте Kandinsky. 
Источник изображения: fusionbrain.ai Нейросеть генерирует непрерывную сцену с движением объектов и фона продолжительностью до шести секунд на скорости 8 кадров в секунду или 32 кадра в секунду. Поддерживается генерация роликов в форматах 16:9, 9:16 и 1:1. Обновлённый алгоритм способен создавать ролики не только по текстовому описанию, но и на основе статического изображения. За счёт этого пользователи имеют больше возможностей для реализации своих творческих задумок. В дополнение к этому пользователь может контролировать динамику генерируемого видео путём изменения параметра «motion score». «Сегодня мы сделали ещё один шаг в будущее видеотворчества. Теперь каждый пользователь Kandinsky Video может воплотить свои идеи и выразить их в видеоформате. С момента запуска первой версии нейросети прошло менее года, и за это время наша команда значительно улучшила такие показатели, как качество и скорость генерации полноценных видеороликов, открывая тем самым безграничные горизонты для креатива», — прокомментировал запуск нового алгоритма Андрей Белевцев, старший вице-президент, руководитель блока «Техническое развитие» Сбербанка. «Яндекс» запустил генеративную нейросеть YandexGPT Lite третьего поколения
28.05.2024 [15:01],
Владимир Фетисов
Компания «Яндекс» официально представила облегчённую версию своей генеративной нейросети третьего поколения YandexGPT 3 Lite. ИИ-сервис доступен клиентам облачной платформы Yandex Cloud через соответствующий API. Нейросеть может быть полезна для разных сценариев использования, например, в чат-ботах, для проверки орфографии или анализа данных. 
Источник изображения: «Яндекс» В компании отметили, что новая версия нейросети подходит для применения в разных сегментах бизнеса. Использование YandexGPT 3 Lite позволит оптимизировать процесс выполнения разных задач, включая консультирование клиентов по телефону и в чатах, подготовку ответов для служб поддержки, генерацию маркетинговых материалов и др. В крупных организациях со сложными бизнес-процессами и большими потоками данных ИИ-сервис может оказаться полезным для анализа информации. По словам разработчиков «Яндекса», YandexGPT 3 Lite по многим параметрам превосходит ИИ-модель предыдущего поколения. В ходе тестирования языковой модели в YaMMLU_ru (русскоязычная версия международного эталонного теста MMLU) было установлено, что YandexGPT 3 Lite даёт на 6 % больше верных ответов, чем модель YandexGPT 2 Lite. Алгоритмы также сравнивались по методу Side by Side, когда им приходится отвечать на одинаковые вопросы, а лучший ответ выбирается экспертной группой. В результате было установлено, что YandexGPT 3 Lite отвечает лучше в 68 % случаев. Ещё в ходе тестирования специалисты оценили, насколько хорошо YandexGPT 3 Lite справляется с задачами классификации, генерации контента, ответами на вопросы и др. Также упоминается, что новый алгоритм допускает меньше орфографических и фактических ошибок по сравнению с YandexGPT 2 Lite. В процессе создания новой ИИ-модели разработчики усовершенствовали все этапы обучения. Был улучшен отбор данных для предварительного этапа обучения, за счёт чего увеличилась доля полезной информации. Также была задействована технология Curriculum Learning для поэтапного усложнения данных. На втором этапе обучения, включающем в себя обучение с подкреплением, была улучшена модель для оценки качества ответов алгоритма. В дополнение к этому в архитектуре нейросети появилась технология Grouped Query Attention для ускорения обработки данных без потери качества. Стоимость использования YandexGPT 3 Lite составляет 20 копеек за 1000 токенов. Новые пользователи Yandex Cloud смогут бесплатно протестировать ИИ-сервис в демо-режиме. Новая модель заменит предыдущую версию алгоритма в течение месяца. Запущен первый в мире биопроцессор из 16 органоидов мозга с удалённым доступом — он обладает высочайшей энергоэффективностью
28.05.2024 [00:50],
Анжелла Марина
Швейцарский биотехнологический стартап FinalSpark запустил уникальную онлайн-платформу, которая впервые в истории предоставляет удалённый доступ к «живому процессору» — 16 органоидам человеческого мозга. Они выступают в качестве биологических процессоров, способных обучаться и обрабатывать информацию. Более того, такие биопроцессоры «потребляют в миллион раз меньше энергии, чем традиционные цифровые процессоры», утверждают в компании. 
Источник изображения: FinalSpark По заявлению FinalSpark, их нейроплатформа потребляет в миллион раз меньше энергии по сравнению с традиционными электронными процессорами. Например, для обучения одной языковой модели LLM вроде GPT-3 требуется около 10 ГВт·ч энергии, что в 6000 раз больше, чем средний житель Европы потребляет за год в своей повседневной жизни. Использование биопроцессоров позволит значительно снизить такие колоссальные затраты энергии применительно к ИИ-моделям и уменьшить негативное воздействие вычислений на окружающую среду. Архитектура нейроплатформы основана на концепции Wetware, которая объединяет аппаратное и программное обеспечение с биологическими компонентами. В её основе лежат четыре многоэлектродные матрицы (МЭА), в которых размещены живые ткани — органоиды, представляющие собой трехмерную клеточную массу тканей головного мозга, поясняет издание Tom's Hardware. Каждая матрица содержит четыре органоида, соединенных с восемью электродами для стимуляции и записи сигналов. Данные передаются через аналогово-цифровые преобразователи Intan RHS 32 с частотой 30 кГц, а для поддержания жизнедеятельности органоидов используется микрофлюидная система и камеры наблюдения. Программный стек позволяет учёным вводить данные и считывать ответы этого уникального биопроцессора. 
Источник изображения: FinalSpark В отличие от кремниевых чипов, которые служат годами, срок службы одного нейронального живого чипа составляет около 100 дней. Хотя изначально органоиды жили всего несколько часов, усовершенствования системы жизнеобеспечения позволила значительно продлить их активное существование. Удалённый доступ к нейроплатформе уже предоставлен 9 научным учреждениям для исследований в области биовычислений. Более 30 университетов также заинтересованы в работе с этой революционной технологией. Для образовательных целей подписка на платформу стоит 500 долларов за пользователя. Коммерциализация биопроцессоров может положить начало новой эре вычислительных систем, более экологичных и близких к естественному интеллекту человека. Google представила ИИ Veo для создания реалистичных видео — Full HD и больше минуты
14.05.2024 [23:46],
Владимир Фетисов
Около трёх месяцев прошло с тех пор как OpenAI представила генеративную нейросеть Sora, которая может создавать реалистичное видео по текстовому описанию. Теперь у Google есть чем ответить: в рамках конференции Google I/O была анонсирована нейросеть Veo. Алгоритм может генерировать «высококачественные» видеоролики с разрешением Full HD продолжительностью более минуты с применением разных визуальных и кинематографических стилей. 
Источник изображения: Google В пресс-релизе Google сказано, что алгоритм Veo обладает «продвинутым пониманием естественного языка», что позволяет ИИ-модели понимать кинематографические термины, такие как «таймлапс» или «съёмка пейзажа с воздуха». Пользователи могут добиться желаемого результата с помощью не только текстовых подсказок, но также «скормить» ИИ изображения или видео, получая в конечном счёте «последовательные и целостные» ролики, в которых на протяжении всего времени движения людей, животных и объектов выглядят реалистично. Генеральный директор ИИ-подразделения Google DeppMind Демис Хассабис (Demis Hassabis) заявил, что пользователи могут корректировать генерируемые ролики с помощью дополнительных подсказок. Кроме того, Google изучает возможность интеграции дополнительных функций, которые позволят Veo создавать раскадровки и более продолжительные видео. Несмотря на сегодняшний анонс Veo, обычным пользователям придётся какое-то время подождать, прежде чем алгоритм станет общедоступным. На данном этапе Google приглашает к тестированию предварительной версии нейросети ограниченно количество создателей контента. Компания хочет поэкспериментировать с Veo, чтобы определить, каким образом следует осуществлять поддержку авторов контента и развивать сотрудничество с ними, давая творческим людям право голоса в разработке ИИ-технологий Google. Некоторые функций Veo в ближайшие несколько недель станут доступны ограниченному числу пользователей сервиса VideoFX, которые подадут заявки на участие в тестировании предварительной версии алгоритма. В будущем Google намерена также добавить некоторые функции Veo в YouTube Shorts. Google представила Gemini Live — ИИ-ассистента с памятью, естественной речью и компьютерным зрением
14.05.2024 [22:12],
Андрей Созинов
Во вторник на конференции Google I/O 2024 была анонсирована новая возможность для ИИ-чат-бота Gemini — функция Gemini Live, которая позволяет пользователям вести «углубленные» голосовые диалоги с Gemini на своих смартфонах. Пользователи могут прерывать Gemini во время его реплик, чтобы задать уточняющие вопросы, и чат-бот будет адаптироваться к речи пользователя в режиме реального времени. Кроме того, Gemini может видеть и реагировать на окружение пользователя, используя фотографии или видео, снятые камерами смартфонов. 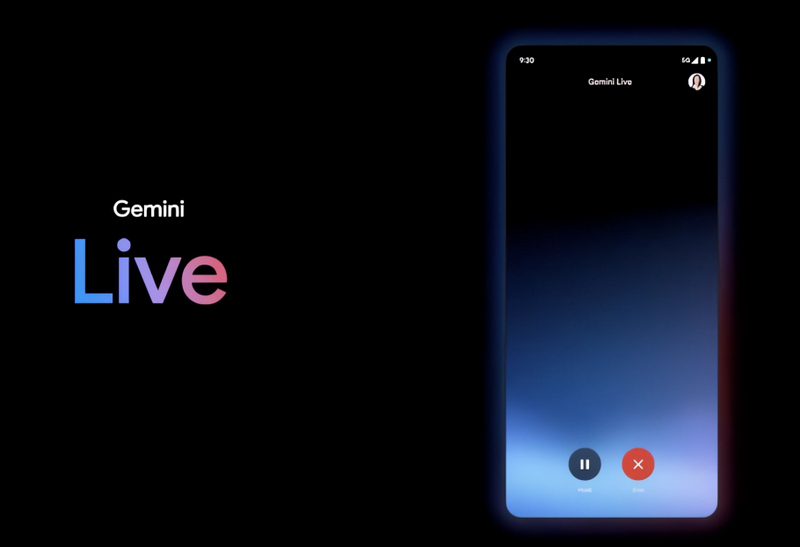
Источник изображений: Google Gemini Live — это в некотором роде соединение платформы компьютерного зрения Google Lens и виртуального помощника Google Assistant, и их дальнейшая эволюция. На первый взгляд Gemini Live не кажется кардинальным обновлением по сравнению с существующими технологиями. Но Google утверждает, что система использует новые методы генеративного ИИ, чтобы обеспечить превосходный, менее подверженный ошибкам анализ изображений, и сочетает эти методы с улучшенным речевым движком для более последовательного, эмоционально выразительного и реалистичного многооборотного диалога. Технические инновации, используемые в Gemini Live, частично связаны с проектом Project Astra, новой инициативой DeepMind по созданию приложений и «агентов» на базе ИИ с поддержкой «понимания» в реальном времени различных источников данных — текста, аудио и изображения. «Мы всегда хотели создать универсального агента, который будет полезен в повседневной жизни, — сказал на брифинге Демис Хассабис (Demis Hassabis), генеральный директор DeepMind. — Представьте себе агентов, которые могут видеть и слышать то, что мы делаем, лучше понимать контекст, в котором мы находимся, и быстро реагировать в разговоре, делая темп и качество взаимодействия гораздо более естественными».  Gemini Live, который будет запущен только в конце этого года, сможет отвечать на вопросы о предметах, находящихся в поле зрения (или недавно попавших в поле зрения) камеры смартфона, например, в каком районе находится пользователь или как называется сломавшаяся деталь велосипеда. Либо пользователь сможет указать системе на часть компьютерного кода, а Live объяснит, за что она отвечает. А на вопрос о том, где могут находиться очки пользователя, Gemini Live скажет, где он видел их в последний раз. А как это облегчит поиск потерянного пульта от телевизора! Live также сможет стать своеобразным виртуальным наставником, помогая пользователям отрепетировать речь к мероприятию, обдумать идеи и так далее. Live может подсказать, какие навыки следует подчеркнуть на предстоящем собеседовании или стажировке, или дать совет по публичному выступлению.  Способность Gemini Live «запоминать», что происходило недавно, стала возможной благодаря архитектуре модели, лежащей в ее основе — Gemini 1.5 Pro, а также, но в меньшей степени, других «специфических» генеративных моделей. У Gemini 1.5 Pro весьма ёмкое контекстное окно, а значит, она может принять и обработать большое количество данных — около часа видео — прежде чем подготовить ответ. В Google отметили, что Gemini Live будет помнить всё, что происходило в последние часы. Gemini Live напоминает генеративный ИИ, применяемый в очках Meta✴, которые аналогичным образом могут просматривать изображения, снятые камерой, и интерпретировать их практически в реальном времени. Судя по демонстрационным роликам, которые Google показала во время презентации, Live также очень похож на недавно обновленный ChatGPT от OpenAI.  Ключевое различие между новым ChatGPT и Gemini Live заключается в том, что решение от Google не будет бесплатным. После запуска Live будет эксклюзивом для Gemini Advanced, более сложной версии Gemini, которая доступна подписчикам плана Google One AI Premium Plan, стоимостью 20 долларов в месяц. Возможно, в качестве отсылки к очкам Meta✴, в одном из демонстрационных роликов Google был показан человек в AR-очках, оснащенных приложением, похожим на Gemini Live. Правда, компания Google, желая избежать очередного провала в сфере умных очков, отказалась сообщить, появятся ли этот или подобный продукт с генеративным ИИ на рынке в ближайшем будущем. Художественная нейросеть YandexART с латентной диффузией обновилась до версии 1.3
24.04.2024 [18:47],
Владимир Мироненко
«Яндекс» представил обновлённую диффузионную нейросеть YandexART 1.3, в которой для генерации графических объектов используется технология латентной диффузии, позволяющая создавать более реалистичные изображения. Кроме того, обучение модели прошло на увеличенном датасете, благодаря чему нейросеть теперь лучше понимает запросы пользователей. 
Источник изображений: «Яндекс» Технология латентной диффузии использует более эффективный подход, чем при каскадной диффузии, формируя промежуточное представление картинки в виде латентного кода — компактного описания, содержащего основную информацию об изображении в сжатой форме, который затем за один шаг разворачивается в полноценное изображение высокого разрешения. Для этого требуется меньше вычислительных ресурсов, а качество итогового изображения получается заметно выше. 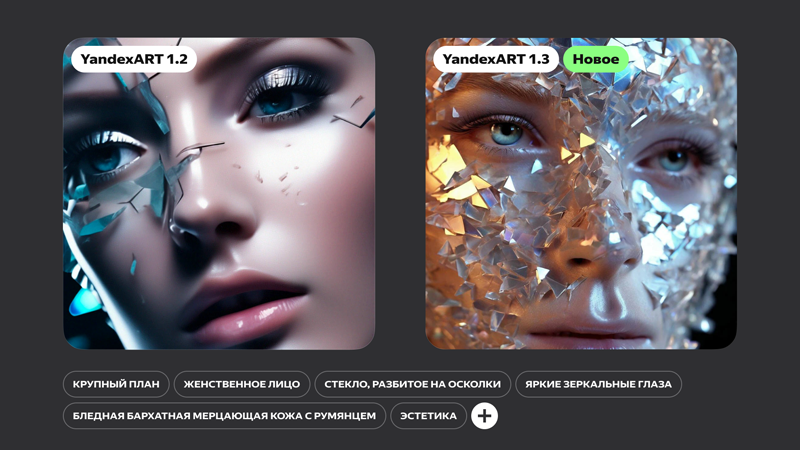 Набор данных, используемых для обучения модели, был увеличен в 2,5 раза до более чем 850 млн пар картинок с текстом. При этом в датасет были добавлены синтетические тексты — сгенерированные нейросетью подробные описания изображений. А чтобы YandexART учитывала больше деталей из промта, в ней теперь используются два текстовых энкодера вместо одного. Они обеспечивают распознавание нейросетью текстовых запросов и их перевод на машинный язык.  Кроме того, благодаря обновлению пользователи получили возможность создавать изображения в разных форматах, таких как 16:9, 4:3 или 3:4. YandexART 1.3 уже применяется в приложении «Шедеврум». В дальнейшем новая версия YandexART появится и в других сервисах «Яндекса». ИИ-приложение Google Gemini сможет отвечать на вопросы в реальном времени
23.04.2024 [14:54],
Владимир Фетисов
Некоторое время назад Google выпустила Android-приложение Gemini, позволяющее взаимодействовать с одноимённой нейросетью компании с помощью мобильных устройств. Теперь же стало известно, что в скором времени продукт получит существенное улучшение, и пользователи сервиса смогут получать ответы на свои запросы в режиме реального времени. 
Источник изображения: StockSnap / pixabay.com ИИ-бот Gemini стал ответом Google на появление ChatGPT от OpenAI. На данный момент Gemini всё ещё уступает ChatGPT во многих аспектах, но разработчики продолжают совершенствовать продукт, который в скором времени также станет доступен в почтовом сервисе Gmail и десктопной версии браузера Chrome. Исследователь приложений, известный под ником AssembleDebug, сообщил, что Google планирует добавить в приложение Gemini функцию «ответов в режиме реального времени». Очевидно, что речь идёт об инструменте генерации ответов на задаваемые пользователем вопросы в режиме онлайн. Исследователь также смог активировать новую опцию в меню настроек Gemini. Это может указывать на то, что функция близка к появлению в стабильной версии приложения. 
Источник изображения: androidpolice.com На данный момент Android-приложение Gemini даёт ответы на пользовательские запросы с некоторой задержкой. В это же время веб-версия алгоритма успешно справляется с тем, чтобы выдавать ответы онлайн. Включение этой функции в приложение нейросети для Android позволит пользователям быстрее получать ответы на интересующие их вопросы. Это также сделает процесс общения с чат-ботом более естественным. Любопытно, что функция ответов в режиме онлайн не единственная, которую AssembleDebug обнаружил в коде бета-версии приложения. Он также нашёл опцию «Использовать местоположение вашего устройства», которая позволит пользователям контролировать доступ Gemini к данным о местоположении. Когда упомянутые нововведения появятся в стабильной версии приложения, пока неизвестно. «Яндекс» запустила «Нейро» — ИИ-сервис для ответов на сложные вопросы с помощью всего интернета
16.04.2024 [14:43],
Владимир Фетисов
Компания «Яндекс» объединила возможности интернет-поиска и больших генеративных моделей, создав новый сервис «Нейро». Он предназначен для ответа на вопросы пользователей, для чего алгоритмы подбирают и изучают необходимые источники в результатах поисковой выдачи. После этого нейросеть YandexGPT 3 анализирует собранные данные и формирует одно ёмкое сообщение со ссылками на соответствующие материалы. 
Источник изображений: «Яндекс» Сервис «Нейро» может отвечать на вопросы, для которых обычно требуется изучение данных в нескольких интернет-источниках. К примеру, когда пользователя интересует вопрос о том, «какие растения могут жить в тёмной комнате и не требуют ежедневного полива» или «стоит ли ехать осенью в Карелию и чем там заняться». Получив ответ на интересующий вопрос, пользователь может продолжить взаимодействие с «Нейро» посредством отправки дополнительных вопросов или уточнения информации в режиме диалога. При этом сервис отвечает на запросы с учётом контекста беседы. Отмечается, что «Нейро» понимает запросы на естественном языке. Для начала взаимодействия с сервисом не требуется подбирать какие-то определённые формулировки. Пользователь может формировать запросы буквально так, как они приходят ему в голову. Текстовые запросы можно дополнять картинками, например, сделать снимок настольной игры и попросить «Нейро» объяснить её правила. 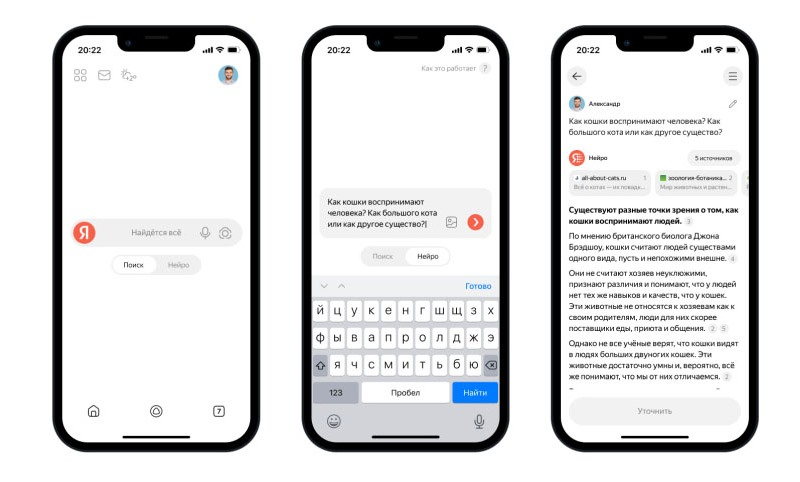 Особенность алгоритма в том, что он берёт факты не из памяти большой языковой модели, а из источников в интернете. Такой подход гарантирует, что в ответах «Нейро» предоставляет свежую и актуальную информацию. Сервис дополняет свои ответы ссылками на источники, которые располагаются отдельным блоком над текстом. Это позволяет пользователям в случае необходимости проверить факты или же более углублённо изучить интересующую тему. В настоящий момент пользователи могут взаимодействовать с сервисом «Нейро» в приложении «Яндекс с Алисой» и в «Яндекс Браузере». Для использования сервиса потребуется авторизоваться с учётной записью «Яндекса» и переключить соответствующий тумблер, расположенный рядом с поисковой строкой. OpenAI попытается заинтересовать Голливуд ИИ-генератором видео Sora
29.03.2024 [19:16],
Владимир Мироненко
Компания OpenAI планирует провести на следующей неделе встречи в Лос-Анджелесе с представителями голливудских студий, руководителями СМИ и агентствами по поиску талантов. Компания хочет сформировать партнёрские отношения с представителями индустрии развлечений и предложить кинематографистам использовать в своей работе новый ИИ-сервис для генерации видео Sora, пишет Bloomberg со ссылкой на источники. 
Источник изображения: Andrew Neel До этого, в конце февраля главный операционный директор OpenAI Брэд Лайткеп (Brad Lightcap) вместе с коллегами демонстрировал в Голливуде возможности Sora, позволяющего генерировать реалистичные видеоролики продолжительностью до минуты на основе текстовых подсказок пользователей. Несколько дней спустя гендиректор OpenAI Сэм Альтман (Sam Altman) посетил мероприятия в Лос-Анджелесе, посвящённые церемонии вручения премии Оскар, на которых, по всей видимости тоже информировал представителей медиабизнеса о возможностях Sora. OpenAI представила ИИ-генератор видео Sora в середине февраля, и его возможности сразу привлекли внимание Голливуда и Кремниевой долины. Хотя нейросеть Sora пока недоступна для широкой публики, ею уже могут воспользоваться некоторые известные актёры и режиссёры. «У OpenAI есть продуманная стратегия работы в сотрудничестве с промышленностью посредством процесса итеративного развёртывания — поэтапного внедрения достижений ИИ — чтобы обеспечить безопасное внедрение и дать людям представление о том, что нас ждёт на горизонте», — сказал представитель OpenAI. «Мы рассчитываем на постоянный диалог с художниками и креативщиками», — добавил он. Конкуренты OpenAI, технологические гиганты Meta✴ Platforms и Google, ранее представили исследовательские проекты по преобразованию текста в видео. Над данной технологией также работают такие ИИ-стартапы, как Runway AI, Pika и Stability AI. Лидирующая в этом сегменте Runway ранее сообщила Bloomberg, что её сервис преобразования текста в видео Runway Gen-2 уже используют миллионы людей, включая профессионалов производственных и анимационных студий, которые полагаются на него при предварительной визуализации и раскадровке. Монтажёры фильмов с помощью сервиса создают видеоролики, сочетая их с другим отснятым контентом для создания рекламных роликов или визуальных эффектов. Google начала показывать результаты ИИ-поиска пользователям, которые не активировали эту функцию
23.03.2024 [15:44],
Владимир Фетисов
Компания Google продолжает развивать собственную поисковую систему, которая ранее получила функцию отображения сводки ответов на введённый запрос и ссылок на источники, подбираемые с помощью генеративного ИИ. Ранее для использования этого нововведения нужно было активировать опцию Search Generative Experience (SGE) на платформе Search Labs. Теперь же подобранные ИИ ответы стали появляться в выдаче всех пользователей поисковика в США. 
Источник изображения: Pixabay По данным источника, Google активировала функцию ИИ-поиска для «небольшого процента поискового трафика в США», в связи с чем пользователи на территории страны могут увидеть сгенерированный нейросетью раздел, даже если они не активировали соответствующую опцию. Напомним, Google представила функцию SGE на ежегодной конференции I/O в мае прошлого года, вскоре после того, как открыла доступ к своему чат-боту Bard, который в настоящее время носит имя Gemini. К ноябрю прошлого года эта функция была развёрнута в 120 странах и могла обрабатывать запросы на множестве языков, но по-прежнему оставалась отключённой по умолчанию. 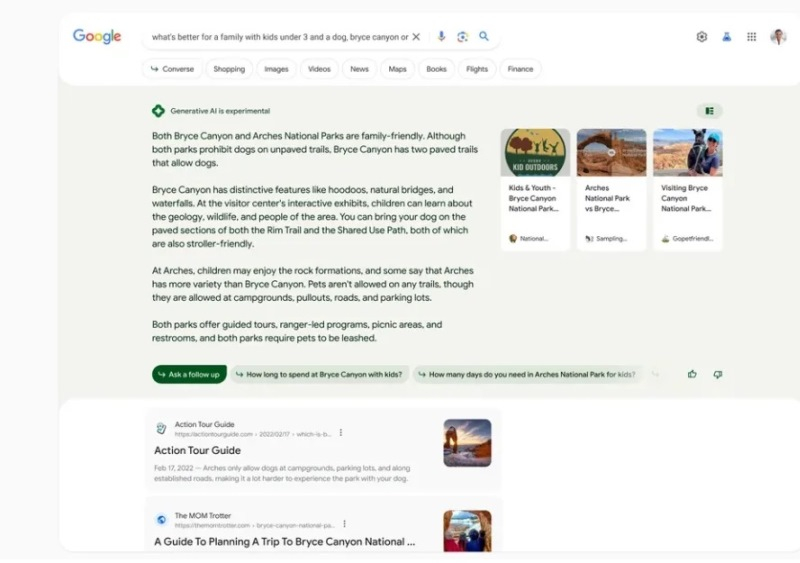
Источник изображения: Google На данном этапе Google будет показывать пользователям сгенерированный ИИ блок при обработке сложных запросов или в случаях, когда поисковик посчитает, что пользователю будет полезно получить информацию по интересующему его вопросу из нескольких источников. Также отмечается, что сгенерированный нейросетью блок будет выводиться только в случаях, когда алгоритм определит, что результат работы ИИ предоставляет более качественную информацию, чем обычная поисковая выдача. Вероятно, Google проводит тестирование функции ИИ-поиска, чтобы получить больше отзывов от пользователей с целью дальнейшей интеграции нейросетей в свой поисковик. Google открыла доступ к мощной нейросети Gemini 1.5 Pro
21.03.2024 [22:01],
Владимир Мироненко
Google открыла доступ к бета-версии нейросети Gemini 1.5 Pro для всех пользователей. Об этом сообщил в социальной сети X ведущий научный сотрудник Google DeepMind Джефф Дин (Jeff Dean). «Сначала мы будем постепенно подключать людей к API, а затем наращивать его. Тем временем разработчики могут опробовать Gemini 1.5 Pro в пользовательском интерфейсе AI Studio прямо сейчас», — рассказал Дин. 
Источник изображения: Google Gemini 1.5 Pro работает со стандартным контекстным окном на 128 000 токенов, хотя, как сообщается, обрабатываемый объём информации можно увеличить до 1 млн токенов. За один раз Gemini 1.5 Pro способна обработать до часа видео, 11 часов аудио, кодовые базы с более чем 30 000 строк кода или более 700 000 слов. В ходе исследования Google также успешно протестировала обработку до 10 млн токенов. Gemini 1.5, использующая архитектуру Transformer и MoE, сочетает в себе сильные стороны обеих моделей. Gemini 1.5 Pro отлично справляется с различными задачами, такими как анализ исторических документов, например, в расшифровке стенограммы миссии «Аполлон-11». Нейросеть способна не только анализировать большие блоки данных, но и быстро находить определённый фрагмент текста внутри них. Также Gemini 1.5 эффективно обрабатывает большие «куски» кода. В интерфейсе AI Studio нейросеть сейчас доступна с ограничением в 20 запросов в день. В тесте Needle In A Haystack (NIAH) нейросеть достигает 99 % успеха в обнаружении конкретных фактов в длинных текстах. А способность учиться в конкретных условиях, продемонстрированная в бенчмарке Machine Translation from One Book (MTOB), делает Gemini 1.5 одним из лидеров в способности к адаптивному обучению. Нейросети помогут в поиске мелкого космического мусора
06.03.2024 [17:39],
Павел Котов
Европейские учёные предложили адаптировать популярные ИИ-алгоритмы систем машинного зрения для анализа сделанных при помощи радаров снимков околоземного пространства и обнаружения на них миниатюрных частиц космического мусора. 
Источник изображения: nasa.gov Исследователи провели эксперимент, применив существующие нейросети, используемые в системах машинного зрения, для анализа данных с европейского радара TIRA — это 47-метровая радиотарелка, которая помогает наблюдать за околоземным пространством и получать изображения, на которых производится поиск космического мусора. Авторы проекта попытались заменить стандартные алгоритмы анализа данных TIRA нейросетями семейства YOLO, которые применяются для поиска движущихся объектов на снимках. Версии нейросетей YOLOv5 и YOLOv8 обучили при помощи массива из 3000 снимков околоземного пространства и проверили их эффективность на примере 600 изображений с радаров, на которых были от одного до трёх частиц космического мусора. Обе нейросети корректно обнаружили от 85 % до 97 % частиц размером от сантиметра при минимальном числе ложных срабатываний. Результат оказался выше того, что демонстрирует стандартный алгоритм TIRA. Учёные сделали вывод, что системы машинного зрения могут успешно применяться для поиска космического мусора в околоземном пространстве и для его отслеживания в реальном времени. Это поможет снизить число инцидентов, связанных с попаданием частиц космического мусора в работающие орбитальные аппараты. По оценкам экспертов, на орбите Земли могут находиться более 170 млн частиц космического мусора. Анонсирована Stable Diffusion 3.0 — ИИ для рисования сменил архитектуру и научился писать
23.02.2024 [00:39],
Андрей Созинов
Компания Stability AI выпустила предварительную версию Stable Diffusion 3.0 — флагманской модели искусственного интеллекта следующего поколения для генерации изображений по текстовому описанию. Stable Diffusion 3.0 будет доступна в разных версиях на базе нейросетей размером от 800 млн до 8 млрд параметров. 
Источник изображений: Stable Diffusion 3.0 В течение последнего года компания Stability AI постоянно совершенствовала и выпускала несколько нейросетей, каждая из которых показывала растущий уровень сложности и качества. Выпуск SDXL в июле значительно улучшил базовую модель Stable Diffusion, и теперь компания собирается пойти значительно дальше. Новая модель Stable Diffusion 3.0 призвана обеспечить улучшенное качество изображения и лучшую производительность при создании изображений из сложных подсказок. Новая нейросеть обеспечит значительно лучшую типографику, чем предыдущие версии Stable Diffusion, обеспечивая более точное написание текста внутри сгенерированных изображений. В прошлом типографика была слабой стороной Stable Diffusion, собственно, как и многих других ИИ-художников. Stable Diffusion 3.0 — это не просто новая версия модели прежней Stability AI, ведь она основана на новой архитектуре. «Stable Diffusion 3 – это диффузионная модель-трансформер, архитектура нового типа, которая аналогична той, что используется в представленной недавно модели OpenAI Sora, — рассказал VentureBeat Эмад Мостак (Emad Mostaque), генеральный директор Stability AI. — Это настоящий преемник оригинальной Stable Diffusion».  Stability AI экспериментирует с несколькими типами подходов к созданию изображений. Ранее в этом месяце компания выпустила предварительную версию Stable Cascade, которая использует архитектуру Würstchen для повышения производительности и точности. Stable Diffusion 3.0 использует другой подход, используя диффузионные модели-трансформеры. «Раньше у Stable Diffusion не было трансформера», — сказал Мостак. Трансформеры лежат в основе большей части современных нейросетей, запустивших революцию в области искусственного интеллекта. Они широко используются в качестве основы моделей генерации текста. Генерация изображений в основном находилась в сфере диффузионных моделей. В исследовательской работе, в которой подробно описываются диффузионные трансформеры (DiT), объясняется, что это новая архитектура для диффузионных моделей, которая заменяет широко используемую магистраль U-Net трансформером, работающим на скрытых участках изображения. Применение DiT позволяет более эффективно использовать вычислительные мощности и превосходить другие подходы к диффузной генерации изображений. Еще одна важная инновация, которой пользуется Stable Diffusion 3.0 — это согласование потоков. В исследовательской работе по сопоставлению потоков объясняется, что это новый метод обучения нейросетей с помощью «непрерывных нормализующих потоков» (Conditional Flow Matching — CNF) для моделирования сложных распределений данных. По мнению исследователей, использование CFM с оптимальными путями транспортировки приводит к более быстрому обучению, более эффективному отбору образцов и повышению производительности по сравнению с диффузионными путями.  Улучшенная типографика в Stable Diffusion 3.0 является результатом нескольких улучшений, которые Stability AI встроил в новую модель. Как пояснил Мостак, качественная генерация текстов на изображения стала возможной благодаря использованию диффузионной модели-трансформера и дополнительных кодировщиков текста. С помощью Stable Diffusion 3.0 стало возможным генерировать на изображениях полные предложения со связным стилем написания текста. Хотя Stable Diffusion 3.0 изначально демонстрируется как технология искусственного интеллекта для преобразования текста в изображение, она станет основой для гораздо большего. В последние месяцы Stability AI также создаст нейросети для создания 3D-изображений и видео. «Мы создаем открытые модели, которые можно использовать где угодно и адаптировать к любым потребностям, — сказал Мостак. — Это серия моделей разных размеров, которая послужит основой для разработки наших визуальных моделей следующего поколения, включая видео, 3D и многое другое». OpenAI представила ИИ-генератор видео Sora, который выдаёт впечатляющие результаты
16.02.2024 [00:05],
Андрей Созинов
OpenAI представила новую нейросеть Sora для генерации видео. Компания утверждает, что Sora «может создавать реалистичные и фантазийные сцены по текстовым инструкциям». Модель преобразования текста в видео позволяет пользователям создавать на базе текстовых описаний фотореалистичные видео длиной до минуты с разрешением Full HD (1920 × 1080 точек). 
Источник изображения: OpenAI Sora способна создавать «сложные сцены с несколькими персонажами, определенными типами движения и точной детализацией объекта и фона», говорится в блоге OpenAI. Компания также отмечает, что нейросеть может понимать, как объекты «существуют в физическом мире», а также «точно интерпретировать реквизит и генерировать убедительных персонажей, выражающих яркие эмоции». Модель может генерировать видео на основе неподвижного изображения, заполнять недостающие кадры в существующем видео или расширять его. Среди демонстрационных роликов, созданных с помощью Sora и показанных в блоге OpenAI, сцена Калифорнии времен золотой лихорадки, видео, снятое как будто изнутри токийского поезда, и другие. Многие из них имеют некоторые артефакты, указывающие на работу искусственного интеллекта. Например, подозрительно движущийся пол в видеоролике о музее. Сама OpenAI говорит, что модель «может испытывать трудности с точным моделированием физики сложной сцены», но в целом результаты довольно впечатляющие. Пару лет назад именно генераторы текста в изображение, такие как Midjourney, лучше всего демонстрировали способности ИИ превращать слова в изображения. Но в последнее время генеративное видео стало улучшаться заметными темпами: такие компании, как Runway и Pika, продемонстрировали впечатляющие модели преобразования текста в видео, а Lumiere от Google, похоже, станет одним из главных конкурентов OpenAI в этой области. Как и Sora, Lumiere предоставляет пользователям инструменты для преобразования текста в видео, а также позволяет создавать видео из неподвижного изображения. В настоящее время Sora доступна только отдельным тестировщикам, которые оценивают модель на предмет потенциального вреда и рисков. OpenAI также предлагает доступ по запросу отдельным художникам, дизайнерам и кинематографистам, чтобы получить обратную связь. Компания отмечает, что существующая модель может неточно имитировать физику сложной сцены и неправильно интерпретировать некоторые случаи причинно-следственных связей. Ранее в этом месяце OpenAI объявила, что добавляет маркировку в свой инструмент преобразования текста в изображение DALL-E 3, но отмечает, что их можно легко удалить. Как и в случае с другими продуктами на базе ИИ, компании OpenAI придется бороться с последствиями того, что поддельные фотореалистичные видео, созданные ИИ, будут выдавать за настоящие. Больше видео, сгенерированных Sora, можно найти здесь. Google выпустила нейросеть Gemini 1.5 с огромнейшим контекстным окном — ИИ за раз осилит весь «Властелин колец»
15.02.2024 [21:20],
Андрей Созинов
Не прошло и двух месяцев с момента запуска передовой нейросети Gemini, а Google уже анонсировала её преемника. Сегодня была представлена большая языковая модель Gemini 1.5, которая сразу же стала доступна для разработчиков и корпоративных пользователей, а в скором времени начнется её распространение среди потребителей. Google ясно дала понять, что хочет использовать Gemini в качестве бизнес-инструмента, персонального помощника и не только.  В Gemini 1.5 много улучшений. Модель Gemini 1.5 Pro, которая ляжет в основу многих сервисов Google, превосходит Gemini 1.0 Pro на 87 % в тестах, и соответственно находится примерно на одном уровне с высококлассной Gemini 1.0 Ultra. При создании новой модели используется набирающий популярность подход «смесь экспертов» (Mixture of Experts — MoE), который подразумевает, что при отправке запроса запускается только часть общей модели, а не вся. Такой подход должен сделать модель более быстрой для пользователя и более эффективной для Google. 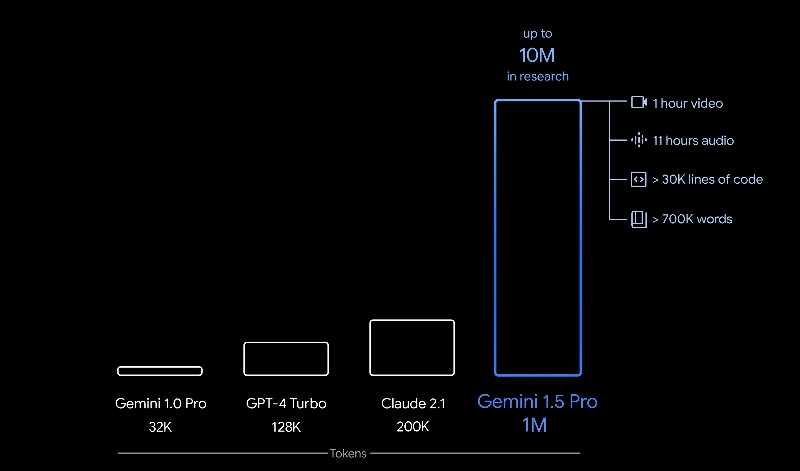 Но в Gemini 1.5 есть одна новая вещь, которая особенно радует всю компанию Google, начиная с генерального директора Сундара Пичаи (Sundar Pichai). Новая версия нейросети имеет огромное контекстное окно, что означает, что она может обрабатывать гораздо более объёмные запросы и просматривать гораздо больше информации одновременно. Размер окна составляет 1 миллион токенов, что намного больше 128 000 токенов у GPT-4 от OpenAI и 32 000 у текущей Gemini Pro. «Это примерно 10 или 11 часов видео, десятки тысяч строк кода», — отметил Пичаи. Ещё он добавил, что исследователи Google тестируют контекстное окно на 10 миллионов токенов — это, например, вся серия «Игры престолов» в одном запросе. В качестве примера Пичаи говорит, что в это контекстное окно можно вместить всю трилогию «Властелин колец». Это кажется слишком специфичным, но, возможно, кто-то в Google проверит, не обнаружит ли Gemini ошибок в преемственности, пытается разобраться в сложной родословной Средиземья. Или ИИ, возможно, сможет понять Тома Бомбадила. Пичаи также считает, что увеличенное контекстное окно будет очень полезно для бизнеса. «Это позволит вам использовать примеры, в которых вы можете добавить много личного контекста и информации в момент запроса, — говорит он. — Считайте, что мы значительно расширили окно запроса». Глава Google представляет себе, что кинематографисты могут загрузить весь свой фильм и спросить у Gemini, что скажут рецензенты, а компании смогут использовать Gemini для обработки массы финансовых документов. «Я считаю это одним из самых больших прорывов, которые мы совершили», — говорит он. Пока что Gemini 1.5 будет доступна только для бизнес-пользователей и разработчиков через Google Vertex AI и AI Studio. Со временем она заменит Gemini 1.0, а стандартная версия Gemini Pro — та, что доступна всем на сайте gemini.google.com и в приложениях Google, — будет заменена на 1.5 Pro с контекстным окном на 128 000 токенов. Чтобы получить миллион, придется доплатить. Google также тестирует безопасность и этические границы модели, особенно в отношении нового увеличенного контекстного окна. Сейчас Google находится в бешеной гонке за создание лучшего инструмента ИИ, в то время как компании по всему миру пытаются определить свою собственную стратегию ИИ и сотрудничать с OpenAI, Google или кем-то ещё. Буквально недавно OpenAI анонсировала «память» для ChatGPT и, похоже, готовится к выходу на рынок веб-поиска. Пока Gemini выглядит впечатляюще, особенно для тех, кто уже работает в экосистеме Google, компании предстоит еще много работы. В конце концов, говорит Пичаи, все эти 1.0 и 1.5, Pro и Ultra, а также корпоративные битвы не будут иметь значения для пользователей. «Люди будут просто потреблять лучший пользовательский опыт, — говорит он. — Это как пользоваться смартфоном, не обращая внимания на процессор под крышкой». Но на данный момент, по его словам, мы всё еще находимся на стадии, когда каждый знает, какой чип находится внутри его телефона, потому что это имеет значение. «Базовые технологии меняются так быстро», — говорит глава Google. — Людям не все равно». |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2024 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews. kz
![]()








 MWC 2018
MWC 2018 2018
2018 Computex
Computex Подписаться
Подписаться